 town
town envs
envs brainshit
brainshitTrouver des synonymes en craquant un orteil
Lucidiot —
Informatique —
2022-07-26
Non, mon cerveau n'est pas en train de craquer. Enfin… pas cette fois.
J'ai moult idées de projets à réaliser sous Windows XP, que je note souvent dans OneNote, quand ce n'est pas directement dans mon planning de publication pour Brainshit. Quand je ne sais pas quoi choisir comme nom pour un projet, je me mets à utiliser un dictionnaire de synonymes, ou thésaurus, en anglais : je prends quelques mots liés au projet, je les passe dans le dictionnaire de synonymes, et une combinaison de synonymes de ces mots me donnera souvent un nom suffisamment étrange pour me plaire.
Avec mon installation actuelle, je dispose de plusieurs dictionnaires et dictionnaires de synonymes hors ligne : Office 2003 me fournit un thésaurus en anglais britannique et en français, et Encarta 2009 fournit un dictionnaire classique en anglais américain et en français. Je peux rechercher dans ces 4 dictionnaires en même temps depuis Word avec le bouton Recherche dans le menu Outils, ou en sélectionnant un mot et en cliquant tout en appuyant sur Alt. Mais j'utilise plus souvent un thésaurus en ligne en anglais, le Big Huge Labs Thesaurus. Ce thésaurus a l'avantage, par rapport à ceux que j'ai hors ligne, d'aussi fournir les mots dont la prononciation est similaire, ceux qui riment avec un mot, ou les antonymes.
Le Big Huge Labs Thesaurus fournit aussi une API assez simple pour demander les synonymes d'un mot. Vu que c'est un thésaurus en ligne, il nécessite un navigateur, le logiciel le plus lourd qui soit sous Windows XP. J'ai récemment installé un SSD dans le ThinkPad R50e, ce qui a amélioré ses performances, mais un navigateur reste toujours beaucoup plus lent qu'une application classique. Vu que j'utilise ce thésaurus régulièrement, et qu'il est vraiment assez simpliste, je me suis dit qu'en quelques heures je pourrais probablement me faire une interface graphique en C# beaucoup plus légère, pour pouvoir rechercher dessus sans avoir besoin d'un navigateur.
Je n'avais pas de nom particulier pour ce projet, alors j'ai tapé thesaurus dans le thésaurus. Il m'a offert comme seul synonyme synonym dictionary, dictionnaire de synonymes, mais il a aussi indiqué que le mot se prononce de façon assez proche à toe crack, l'intervalle entre les orteils. J'ai donc baptisé ce projet ToeCracker, craqueur d'orteils.
J'ai écrit mon concept pour ce projet dans OneNote, et j'en ai même fait un design possible sur Visio. J'y avais notamment décidé de ne pas utiliser l'API, car elle nécessite d'obtenir une clé, et même si une clé peut être obtenue gratuitement, ne pas avoir besoin de clé du tout serait beaucoup plus simple. Et rien ne m'empêche de faire une requête HTTP au site web directement et de lire le contenu de la page en HTML : ce site est suffisamment simple pour se permettre ça. Et puis j'ai complètement abandonné l'idée, perdue dans mes notes.
Il y a quelques semaines, alors que je n'arrivais pas à dormir pendant une vague de chaleur, je suis retombé sur cette idée et j'ai décidé d'au moins commencer le projet. Finalement, 6 heures plus tard, le projet était terminé, avec un installeur, de l'internationalisation pour que le thésaurus aie un peu de texte en français, etc.
Lecture des résultats de recherche
Puisque je ne vais pas utiliser l'API, je vais devoir lire du HTML. Je veux comme d'habitude une compatibilité avec Windows 2000 et Windows XP, donc j'utilise .NET Framework 2.0, et lire du HTML directement avec rien d'autre que les fonctionnalités de base de .NET Framework 2.0, sans dépendre d'Internet Explorer, est assez compliqué.
On peut par contre lire du XML sans problèmes. Du HTML est parfois du XML, soit quand il est très bien écrit, soit quand il respecte les standards XHTML. Dans notre cas, les pages renvoyées par le thésaurus ne sont hélas ni en XHTML ni bien écrites, donc un parseur XML pleurerait face à ces données.
Avant que je ne me retrouve à essayer encore d'écrire une expression régulière horrible pour lire tout le contenu de la page, j'ai pris la peine de lire la portion de la page qui contient uniquement les résultats de recherche :
<div class="results">
<h2 class="center">thesaurus</h2>
<h3>noun</h3>
<ul class="words">
<li><a href="/synonym finder">synonym finder</a></li>
<li><a href="/wordbook">wordbook</a></li>
</ul>
<h3>sounds kind of like</h3>
<ul class="words">
<li><a href="/take charge">take charge</a></li>
<li><a href="/tau cross">tau cross</a></li>
<li><a href="/theocracy">theocracy</a></li>
<li><a href="/tigerish">tigerish</a></li>
<li><a href="/tigers">tigers</a></li>
<li><a href="/tigress">tigress</a></li>
<li><a href="/tigris">tigris</a></li>
<li><a href="/toe crack">toe crack</a></li>
<li><a href="/tsoris">tsoris</a></li>
<li><a href="/tsuris">tsuris</a></li>
<li><a href="/tughrik">tughrik</a></li>
<li><a href="/tugrik">tugrik</a></li>
</ul>
<h3>rhymes with</h3>
<ul class="words">
<li><a href="/abacus">abacus</a></li>
<li><a href="/abruptness">abruptness</a></li>
<!-- ... des dizaines d'autres mots ... -->
</ul>
</div>
Dans le cas où un mot n'est pas trouvé, on reçoit une réponse HTTP 200 OK, parce que les codes d'erreur HTTP ne sont jamais respectés par personne, et on obtiendra les résultats suivants :
<div class="results">
<h3 class="center">Not found</h3>
</div>
On notera donc que dans tous les cas, la seule portion de la page qui nous intéresse se trouve dans ce <div class="results">, et qu'on peut donc ignorer tout le reste. Si on ne prend que le HTML contenu dans ce <div>, alors il représente du XML valide et on peut le lire avec un parseur XML.
Mon algorithme pour lire les résultats de recherche est donc le suivant :
- Rechercher la première occurence de
<div class="results">dans le contenu de la page, en utilisant juste la méthodeString.IndexOfet pas une regex. - Recherche la première occurrence de
</div>après le<div class="results">. - Prendre la portion du texte entre ces deux emplacements, en incluant le
<div>et</div>, et charger ça comme du XML. - Lire chaque balise contenue dans le
div:- Si on a une balise
h3, alors on commence un groupe de mots. Le texte dans la balise est sauvegardé comme nom du groupe de mots. - Si on a une balise
ul, on lit chaque baliseliqu'elle contient et on ajoute des mots dans une liste. - Si on a une autre balise
h3, le groupe de mots actuel est sauvegardé dans un dictionnaire (Dictionary<string, string[]>), avec le nom en clé et la liste en valeur, et on repart d'une liste de mots vierge. Si la liste de mots était vide, on ne sauvegarde rien. - Si on a une balise inconnue, on l'ignore.
- Si on a une balise
ulalors qu'on n'a pas encore eu deh3, on cause une erreur.
- Si on a une balise
Puisqu'on ignore les groupes de mots vides, la lecture du <h3 class="center">Not found</h3> renverra juste un dictionnaire vide, donc c'est assez facile de détecter qu'il n'y a aucun résultat et d'afficher une erreur.
J'ai plus tard découvert également l'existence de sous-groupes de mots, puisque le thésaurus est aussi capable d'afficher les antonymes ou des termes liés au mot ou similaires à ce mot. Ces mots sont regroupés par des balises <h4>, pour qu'ils soient quand même groupés par fonction grammaticale. Pour le mot dead par exemple, on aura alive comme antonyme en tant qu'adjectif, et living comme antonyme en tant que nom. J'ai donc ajouté un cas supplémentaire ajoutant juste des sous-groupes dans la liste des mots, en majuscules et séparés par une ligne vide. L'interface graphique les détecte et ne les considère pas vraiment comme des mots, donc on ne peut pas interagir avec.
Installation
Lorsque je publie une nouvelle version, elle apparaît dans la page des releases. J'y publie le programme d'installation, appelé ToeCrackerSetup.msi. Vous pouvez télécharger ce programme et l'exécuter pour lancer l'installation, et il ajoutera un raccourci vers ToeCracker dans le menu Démarrer. Vous pouvez désinstaller le programme en toute sécurité depuis le panneau de configuration, comme avec tout programme classique.
Utilisation
L'interface est très simpliste : une barre de recherche en haut pour saisir des mots, et plusieurs onglets représentant chaque groupe de mots, contenant chacun une liste de mots.
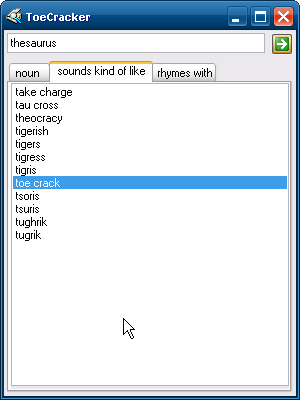
On peut utiliser le clic droit sur un mot pour le copier dans le Presse-papiers ou l'utiliser comme terme de recherche pour continuer les recherches.
Notez que les titres des groupes de mots et les textes d'aide des boutons et de la barre de recherche sont tous internationalisés, c'est-à-dire qu'il est possible de les traduire dans la langue de l'utilisateur. Cela peut aider quand on veut utiliser ce thésaurus anglais alors qu'on ne parle pas anglais.
Conclusion
Voilà donc un second outil pour XP terminé, encore quelque chose d'assez court à développer. J'aime bien ces petits projets d'utilitaires qui m'apportent immédiatement quelque chose et peuvent être faits en un week-end. J'ai encore moult idées de projets, et rien qu'en écrivant cet article j'ai trouvé deux idées d'améliorations possibles pour ce projet ainsi que pour deux autres projets dont je n'ai pas encore parlé... J'ai du pain sur la planche.
Notons que je ne compte pas prendre en charge des thésaurus d'autres langues pour le moment, tout simplement parce que je n'en ai pas besoin. Si vous en connaissez des bons qui fournissent soit une API sans aucune clé ou aucune configuration nécessaire, soit des pages web très faciles à lire, et que le format de retour pourrait facilement être adapté à l'interface actuelle, ça pourrait cela dit être envisageable, surtout s'il y a des services de ce genre pour un bon nombre de langues.
C'est chouette ! Hors de mes besoins actuels malheureusement, mais j'apprécie la démarche.