 town
town envs
envs brainshit
brainshitAfficher une carte des réseaux Wi-Fi
Lucidiot —
Informatique —
2021-07-18
Enfin autre chose que de l'import de données, mais toujours plus de SQL. Et un œuf.
On a beaucoup parlé précédemment de l'import de données de scans de réseaux Wi-Fi, mais on n'en est toujours pas arrivés à l'exploitation de ces données. Il est grand temps de le faire !
Pour rappel, notre base de données en est pour l'instant à trois tables :
trip- Les coordonnées GPS enregistrées à un moment donné, avec optionnellement une précision.
accesspoint- Les points d'accès uniques qui ont été scannés.
measurement- Le scan d'un point d'accès à un moment donné, avec entre autres la puissance reçue ou le canal Wi-Fi utilisé. Cela peut aussi inclure des coordonnées GPS, auquel cas elles prennent la priorité sur celles dans
trip.
L'objectif du jour est de pouvoir représenter les réseaux Wi-Fi sur une carte. On veut donc, pour chaque accesspoint, récupérer les meilleures coordonnées GPS que nous avons depuis measurement ou depuis trip. Nous n'allons dans un premier temps considérer que measurement et nous reviendrons plus tard sur trip.
Trouver la meilleure mesure
Il nous faut d'abord définir ce que veut dire « meilleures » coordonnées. Ce critère peut varier en fonction de ce que vous voudriez faire de cette base de données, mais pour nous, ce n'est pas la précision du GPS qui compte, c'est la qualité du signal. Nous voulons pouvoir revenir sur place et retrouver facilement un réseau, ou lorsqu'il s'agit de cartographier sur OpenStreetMap un réseau ouvert, pouvoir rapidement trouver le commerce ou le lieu public qui offre ce réseau, donc là où il est le plus fort, c'est là où c'est le plus intéressant.
Commençons donc par trouver la meilleure mesure pour chaque point d'accès selon ce critère. On pourrait se dire qu'en regroupant les mesures par point d'accès, puis en triant par signal reçu, on pourra obtenir immédiatement la meilleure mesure :
SELECT *
FROM measurement
GROUP BY bssid
ORDER BY signal DESC
Mais PostgreSQL ne sera pas content !
ERROR: column "measurement.timestamp" must appear in the GROUP BY clause or be used in an aggregate function
En utilisant GROUP BY, on restreint toutes les colonnes qu'on peut renvoyer à celles qui sont incluses dans le GROUP BY ou à des fonctions d'agrégation comme COUNT ou MAX. Mais PostgreSQL nous permet d'implémenter nos propres fonctions d'agrégation, donc on pourrait en créer une qui récupère la meilleure valeur, quelque chose comme SELECT best(signal, 'DESC'). Sauf qu'en fait, on vient de réinventer la roue.
SQL:2003 a standardisé la notion de Window Functions, ou fonctions fenêtrées, qui fonctionnent comme des agrégations mais sur des sous-parties du résultat. Au lieu de travailler sur toutes les lignes sélectionnées et de ne pouvoir renvoyer qu'un résultat, ces fonctions peuvent travailler sur des partitions de données (des découpages par colonne), des intervalles (toutes les 10 lignes par exemple), ou des groupes (par exemple la ligne courante ainsi que celle avant et après). Il n'y a pas tant que ça de fonctions fenêtrées disponibles, mais il y en a assez pour faire beaucoup de choses et combler des trous ou permettre des optimisations.
Dans notre cas, nous pouvons utiliser la fonction first_value(…), partitionner par point d'accès, et trier par signal :
SELECT bssid, first_value(timestamp) OVER (PARTITION BY bssid ORDER BY signal DESC)
FROM measurement
La clé primaire de measurement est une clé composée, c'est-à-dire qu'elle utilise deux colonnes : le bssid qui identifie le point d'accès de façon unique, et le timestamp qui identifie quand on a pris la mesure. On considère qu'on ne peut pas faire plus d'une mesure par milliseconde et par réseau. Comme on ne peut pas utiliser first_value(*) ou avec plusieurs colonnes, on va seulement récupérer le timestamp de la mesure qui a eu le meilleur signal pour ce réseau. On peut alors récupérer toutes les données de ces mesures en utilisant cette requête comme sous-requête, et on peut associer ça aux données de chaque point d'accès :
SELECT accesspoint.*, measurement.*
FROM measurement
INNER JOIN accesspoint USING (bssid)
WHERE (bssid, timestamp) IN (
SELECT bssid, first_value(timestamp) OVER (PARTITION BY bssid ORDER BY signal DESC)
FROM measurement
);
On peut déjà lancer cette requête et observer le résultat dans pgAdmin ou dans un outil GIS comme QGIS.
Gérer l'imprécision
Nous n'affichons actuellement que des points, donc des coordonnées exactes. Or, nos coordonnées GPS ne sont pas exactes ! Il y a un certain niveau d'imprécision, qui dépend de la bonne réception des satellites. En fait, rien qu'à faire tourner cette requête sur pgAdmin, je vois des points sur la carte qui passent à travers des immeubles sont même sont dans l'eau !
Nous stockons déjà cette information de précision, en mètres, dans la colonne precision. On pourrait s'en servir pour afficher des cercles.
La notion de cercle est plutôt inexistante dans PostGIS, vu que tout est plutôt conçu pour travailler avec des points, lignes et polygones ; mais on peut faire des approximations. On peut demander à PostGIS de générer un polygone qui représente approximativement un cercle autour du point, ce qui est un cas parmi d'autres géré par ST_Buffer. Cette fonction renvoie un polygone qui représente tous les points se trouvant à une distance maximale d'un point, d'une ligne, ou d'un autre polygone, donc dans notre cas ce sera un cercle.
SELECT bssid, timestamp, ssid, signal, ST_Buffer(position, precision)
FROM measurement
INNER JOIN accesspoint USING (bssid)
WHERE (bssid, timestamp) IN (
SELECT bssid, first_value(timestamp) OVER (PARTITION BY bssid ORDER BY signal DESC)
FROM measurement
);
Nous profitons ici du fait que nos positions utilisent le SRID 4326, qui désigne le système de coordonnées WGS84 classique ; ST_Buffer mesurera les distances dans ce système en mètres.
Mais si on exécute la requête, on tombe sur quelque chose de… bizarre :
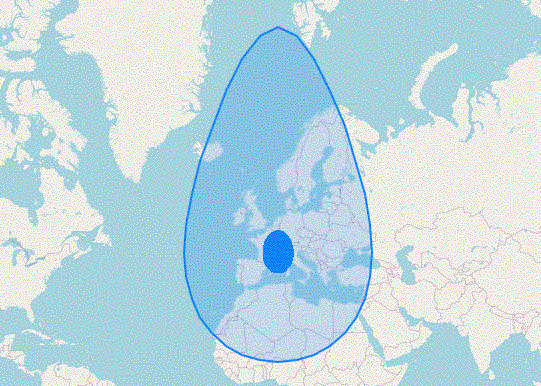
Pâques, c'était il y a plus de trois mois ! J'ai demandé des cercles, pas des œufs !
J'ai un peu menti. En fait, ST_Buffer ne comprend pas qu'on travaille dans un environnement géographique parce qu'on ne lui donne que des géométries ; pour lui, un mètre va donc correspondre en fait à un degré de latitude ou de longitude, d'où la taille énorme des polygones. En plus, comme la Terre n'est pas aussi plate que certains peuvent le croire, les cercles prennent la forme d'œufs car ils se déforment de plus en plus en s'approchant des pôles.
On peut corriger ça simplement en modifiant la position pour en faire une geography : ST_Buffer(position::geography, precision)
Cela dit, en faisant cela, on s'aperçoit que l'on perd à peu près la moitié des points ; l'information de précision a été pendant un bon moment manquante de nos données pour diverses raisons, donc on doit gérer le cas où la précision est manquante. On peut juste continuer à renvoyer le point quand on ne peut pas le transformer en cercle :
SELECT
bssid,
timestamp,
ssid,
signal,
CASE
WHEN precision IS NULL THEN position::geography
ELSE ST_Buffer(position::geography, precision)
END AS geo
FROM measurement
INNER JOIN accesspoint USING (bssid)
WHERE (bssid, timestamp) IN (
SELECT bssid, first_value(timestamp) OVER (PARTITION BY bssid ORDER BY signal DESC)
FROM measurement
);
Associer les coordonnées manquantes
Avec tout ça, nous n'avons récupéré les meilleures coordonnées que pour 10% de nos réseaux Wi-Fi ! Pour les 90% restants, les données GPS sont absentes de measurement, et nous allons devoir utiliser trip.
La table trip ne contient que trois colonnes : un timestamp, des coordonnées GPS et une précision, qui là aussi peut être absente (bien que ce soit bien plus rare). Alors on pourrait se dire qu'il faut faire une jointure supplémentaire, en utilisant un LEFT JOIN puisqu'on pourrait se dire que les coordonnées ne seront pas dans trip si elles étaient dans measurement :
SELECT
bssid,
timestamp,
ssid,
signal,
CASE
WHEN COALESCE(measurement.precision, trip.precision) IS NULL
THEN COALESCE(measurement.position, trip.position)::geography
ELSE ST_Buffer(
COALESCE(measurement.position, trip.position)::geography,
COALESCE(measurement.precision, trip.precision)
)
END AS geo
FROM measurement
INNER JOIN accesspoint USING (bssid)
LEFT JOIN trip USING (timestamp)
WHERE (bssid, timestamp) IN (
SELECT bssid, first_value(timestamp) OVER (PARTITION BY bssid ORDER BY signal DESC)
FROM measurement
);
On utilise des COALESCE pour donner la priorité aux coordonnées de measurement, et sinon retomber sur trip. Bien que cette requête puisse s'exécuter tout à fait normalement, on constatera qu'exactement aucun nouveau réseau n'a été ajouté à notre carte.
En fait, on est en train de considérer que les coordonnées GPS sont collectées à l'exacte même milliseconde que lorsqu'on scanne un réseau Wi-Fi. Cependant, les coordonnées dans trip proviennent soit de mon téléphone, qui sera complètement désynchronisé avec les micro-contrôleurs (surtout à la milliseconde près), soit de la Poutre, qui aura acquis cette position pendant les quelques secondes d'attente avant de scanner les réseaux, donc rien ne peut jamais être bien décalé. Ce qu'on doit vraiment rechercher, ce sont les coordonnées récupérées à l'instant le plus proche de celui de la mesure du réseau Wi-Fi.
On pourrait mesurer la distance entre l'instant de la mesure et celui des coordonnées GPS comme la valeur absolue de la soustraction des deux instants. Comme la soustraction de deux timestamp renvoie un interval et que les intervalles de temps ne prennent pas en charge la valeur absolue, on va utiliser EXTRACT(EPOCH FROM …) pour en récupérer le nombre de secondes qui les sépare et en faire une valeur absolue :
ABS(EXTRACT(EPOCH FROM measurement.timestamp - trip.timestamp))
Mais comment intégrer ça à notre requête globale ? On pourrait essayer d'utiliser une fonction fenêtrée à nouveau, pour prendre pour chaque mesure les coordonnées GPS les plus proches :
SELECT
DISTINCT ON (bssid)
bssid,
measurement.timestamp,
ssid,
signal,
CASE
WHEN COALESCE(
measurement.precision,
first_value(trip.precision) OVER (
PARTITION BY measurement.timestamp
ORDER BY ABS(EXTRACT(EPOCH FROM measurement.timestamp - trip.timestamp))
)
) IS NULL
THEN COALESCE(
measurement.position,
first_value(trip.position) OVER (
PARTITION BY measurement.timestamp
ORDER BY ABS(EXTRACT(EPOCH FROM measurement.timestamp - trip.timestamp))
)
)::geography
ELSE ST_Buffer(
COALESCE(
measurement.position,
first_value(trip.position) OVER (
PARTITION BY measurement.timestamp
ORDER BY ABS(EXTRACT(EPOCH FROM measurement.timestamp - trip.timestamp))
)
)::geography,
COALESCE(
measurement.precision,
first_value(trip.precision) OVER (
PARTITION BY measurement.timestamp
ORDER BY ABS(EXTRACT(EPOCH FROM measurement.timestamp - trip.timestamp))
)
)
)
END AS geo
FROM measurement
INNER JOIN accesspoint USING (bssid)
CROSS JOIN trip
WHERE (bssid, measurement.timestamp) IN (
SELECT bssid, first_value(measurement.timestamp) OVER (PARTITION BY bssid ORDER BY signal DESC)
FROM measurement
);
On utilise non plus un LEFT JOIN mais un CROSS JOIN, aussi connu sous le nom de FULL OUTER JOIN ou FULL JOIN. Ce type de jointure est le plus bête de tous : pour chaque ligne de la première table, combiner avec toutes les autres lignes de la seconde table sans aucun filtrage. Cela nous permet d'utiliser deux fois deux fonctions fenêtrées pour récupérer la position et la précision de la coordonnée la plus proche. Vu que ces fonctions fenêtrées ne feront pas les agrégations qu'on aurait avec un GROUP BY, on utilise un DISTINCT ON pour dédupliquer les lignes et n'avoir qu'une seule ligne par réseau.
J'ai complètement inventé cette requête juste pour cet article et pour justifier la suite, parce que j'avais trouvé une bien meilleure solution sur StackOverflow il y a un moment. Je viens d'essayer de l'exécuter, et je me suis retrouvé à devoir utiliser pg_terminate_backend pour la tuer parce qu'elle prenait trop de temps et utilisait toutes les ressources du serveur.
Un petit EXPLAIN sur la requête m'indique que PostgreSQL prédit qu'environ 11.5 milliards de lignes devront être traitées, le tout après trois scans séquentiels (trois lectures complètes des tables sans utiliser des index ni la moindre autre optimisation), avec des jointures à base de boucles imbriquées en pagaille, plusieurs tris, plusieurs agrégations, bref l'idéal pour tout exploser. En fait, même en retirant la gestion des coordonnées depuis measurement pour retirer les COALESCE, en supprimant la jointure sur accesspoint et en récupérant directement first_value(trip.position) sans essayer de dessiner un cercle, ça explose aussi.
Utiliser une jointure latérale
Reformulons différemment ce que j'essaie de faire avec tous ces first_value : Pour chaque meilleure mesure effectuée sur un point d'accès, trouver la coordonnée GPS à l'instant le plus proche de celui de la mesure. C'est quelque chose qui s'exprimerait plutôt bien comme une boucle, et SQL dispose d'une fonctionnalité pour les sous-requêtes qui permet de vraiment les faire se comporter comme des boucles : les jointures latérales.
Dans les jointures classiques qui inclueraient des sous-requêtes (INNER JOIN (SELECT …) AS a), chaque sous-requête est évaluée de façon totalement indépendante ; autrement dit, elles ne peuvent pas faire référence à d'autres tables ou requêtes mentionnées précédemment dans la requête principale. Mais avec le mot-clé LATERAL, on peut autoriser cet accès. Cela nous permettrait donc de faire une jointure sur le résultat d'une requête pour chaque meilleure mesure :
SELECT
bssid,
measurement.timestamp,
ssid,
signal,
CASE
WHEN COALESCE(measurement.precision, nearest_trip.precision) IS NULL
THEN COALESCE(measurement.position, nearest_trip.position)::geography
ELSE ST_Buffer(
COALESCE(measurement.position, nearest_trip.position)::geography,
COALESCE(measurement.precision, nearest_trip.precision)
)
END AS geo
FROM measurement
INNER JOIN accesspoint USING (bssid)
CROSS JOIN LATERAL (
SELECT * FROM trip
ORDER BY ABS(EXTRACT(EPOCH FROM measurement.timestamp - trip.timestamp))
LIMIT 1
) AS nearest_trip
WHERE (bssid, measurement.timestamp) IN (
SELECT bssid, first_value(measurement.timestamp) OVER (PARTITION BY bssid ORDER BY signal DESC)
FROM measurement
);
La requête est déjà un peu plus buvable que tout à l'heure. La sous-requête dans la jointure latérale inclut un LIMIT 1, ce qui veut dire que pour chaque meilleure mesure, je ne récupère qu'une seule meilleure coordonnée, donc on ne travaille plus sur des milliards de lignes et je peux retirer le DISTINCT. EXPLAIN semble lui aussi être un peu plus optimiste quant au résultat de la requête.
La requête a pris 3 minutes et 36 secondes pour 30 000 réseaux. Le plus a été un scan séquentiel sur les 28 000 lignes de trip qui s'est exécutée une fois pour chaque réseau ; plus de 800 millions de lignes lues donc, pour n'en récupérer qu'une seule à chaque lecture. C'est assez atroce, mais ça a au moins le mérite de fonctionner…
Optimiser la recherche de voisin le plus proche
Le type de filtrage que je fais, à base de distance entre deux valeurs, est une recherche de voisin le plus proche, ou nearest-neighbor. Il est déjà possible de faire des recherches de voisin le plus proche avec des points dans PostGIS par exemple, via l'opérateur <->. Je pourrais par exemple rechercher le point d'accès le plus proche d'un point défini :
SELECT accesspoint.*
FROM accesspoint
INNER JOIN measurement USING (bssid)
ORDER BY position <-> 'SRID=4326;POINT(45.123456 3.123456)'::geometry
LIMIT 1;
Il est possible d'optimiser cela pour des recherches sur des ensembles de données plus grands à l'aide d'un index GIST :
CREATE INDEX trip_gist ON trip USING GIST (position);
Alors pourquoi ne pourrais-je pas faire exactement la même chose avec un timestamp ? Et bien parce que l'opérateur de distance n'est pas disponible pour ce type. Il n'est disponible que pour les types géométriques de PostgreSQL et ceux de PostGIS. Je pourrais implémenter un opérateur personnalisé pour ça, j'ai déjà joué avec les opérateurs, les classes d'opérateurs, les familles d'opérateurs, etc., mais ça n'apporterait toujours aucune optimisation et je ne pourrais pas utiliser d'index dessus.
Fort heureusement, il existe une extension qui implémente l'opérateur de distance pour un grand nombre de types pour lesquels un opérateur de distance serait logique, en plus de leur optimisation via GIST : btree_gist.
CREATE EXTENSION IF NOT EXISTS 'btree_gist';
CREATE INDEX trip_gist ON trip USING GIST (timestamp);
SELECT
bssid,
measurement.timestamp,
ssid,
signal,
CASE
WHEN COALESCE(measurement.precision, nearest_trip.precision) IS NULL
THEN COALESCE(measurement.position, nearest_trip.position)::geography
ELSE ST_Buffer(
COALESCE(measurement.position, nearest_trip.position)::geography,
COALESCE(measurement.precision, nearest_trip.precision)
)
END AS geo
FROM measurement
INNER JOIN accesspoint USING (bssid)
CROSS JOIN LATERAL (
SELECT * FROM trip
ORDER BY measurement.timestamp <-> trip.timestamp
LIMIT 1
) AS nearest_trip
WHERE (bssid, measurement.timestamp) IN (
SELECT bssid, first_value(measurement.timestamp) OVER (PARTITION BY bssid ORDER BY signal DESC)
FROM measurement
);
Cette requête ne prend plus que 13 secondes à s'exécuter, ce qui est 16 fois plus rapide. L'usage en conditions réelles a montré que nous utilisons plus souvent des filtres sur le chiffrement des réseaux pour trouver seulement ceux qui nous intéressent, et le planificateur de requêtes de PostgreSQL est suffisamment intelligent pour faire passer les requêtes LATERAL en dernières, donc les filtres font passer les requêtes à 0.5 à 3 secondes en moyenne, ce qui est tout à fait acceptable.
Requête finale
Les COALESCE font que lorsque la précision des coordonnées données dans measurement n'est pas indiquée, mais qu'il y a des coordonnées, et que celles dans nearest_trip ont une précision, alors on se retrouve avec un cercle dont les coordonnées sont celles de measurement et la précision celle de nearest_trip, ce qui n'a aucun sens. Le CASE utilisé pour récupérer le point ou le cercle a donc été modifié.
Le système de recherche des coordonnées les plus proches peut parfois donner des valeurs totalement bidon, par exemple en donnant des coordonnées qui ont été enregistrées une semaine après l'enregistrement du scan, donc un filtre a été ajouté pour limiter la distance entre les timestamps à 15 secondes. Cela a par contre pour effet de tripler le temps d'exécution des requêtes !
Puisque les points et cercles sont cliquables dans la carte interactive de pgAdmin, on a ajouté des colonnes pour pouvoir lire directement la précision ainsi que la distance entre la mesure et les coordonnées quand elles proviennent de la recherche dans trip.
Une nouvelle table a été créée, blocklist, qui n'a qu'une colonne ssid et qui nous permet d'ignorer les réseaux très courants comme FreeWifi, SFR WiFi FON, orange, FlixBus WiFi qui ne font que polluer nos cartes et n'ont pas d'intérêt pour le moindre de nos objectifs, ce qui accélère du coup les requêtes en supprimant 20 à 30% des réseaux.
Et le tout a été enregistré dans une vue, avec quelques vues dépendant de celle-ci pour ajouter des filtres communs :
CREATE VIEW all_map AS
SELECT
timestamp,
bssid,
ssid,
encryption,
password,
signal,
CASE
WHEN measurement.position IS NULL
THEN nearest_trip.precision
ELSE measurement.precision
END AS precision,
CASE
WHEN measurement.position IS NULL
THEN nearest_trip.distance
ELSE NULL::interval
END AS distance,
CASE
WHEN measurement.position IS NOT NULL AND measurement.precision IS NOT NULL
THEN ST_Buffer(measurement.position::geography, measurement.precision)
WHEN measurement.position IS NOT NULL AND measurement.precision IS NULL
THEN measurement.position::geography
WHEN nearest_trip.precision IS NOT NULL
THEN ST_Buffer(nearest_trip.position::geography, nearest_trip.precision)
ELSE nearest_trip.position::geography
END AS position
FROM (
SELECT timestamp, bssid, channel, signal, position, precision
FROM measurement
WHERE (bssid, timestamp) IN (
SELECT bssid, first_value(timestamp) OVER (PARTITION BY bssid ORDER BY signal DESC) AS first_value
FROM measurement
)
) measurement
INNER JOIN accesspoint USING (bssid)
CROSS JOIN LATERAL (
SELECT
trip.position,
trip.precision,
trip.timestamp <-> measurement.timestamp AS distance
FROM trip
WHERE trip.timestamp <-> measurement.timestamp < '00:00:15'::interval
ORDER BY (trip.timestamp <-> measurement.timestamp)
LIMIT 1
) nearest_trip
WHERE ssid NOT IN (SELECT ssid FROM blocklist);
CREATE VIEW open_map AS
SELECT * FROM all_map WHERE encryption = 'NONE';
CREATE VIEW wep_map AS
SELECT * FROM all_map WHERE encryption = 'WEP' AND password IS NULL;
Et en voici le résultat :
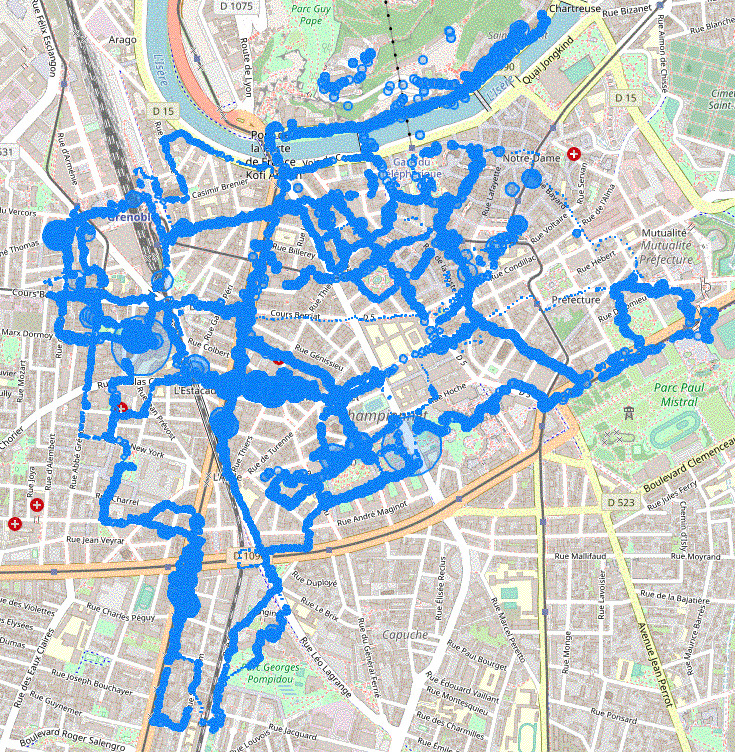
Maintenant que nous sommes armés d'une belle carte, il va falloir l'utiliser. On verra ça la prochaine fois…
Commentaires
Il n'y a pour l'instant aucun commentaire. Soyez le premier !